为什么 RVC 变声后别人听不到?手把手教你配置虚拟声卡(VB-Audio)实现全局变声
解决RVC变声后他人听不见的问题,手把手教你配置VB-Audio虚拟声卡实现全局变声,解决音频路由闭环问题。
实时AI变声,低延迟,海量音色
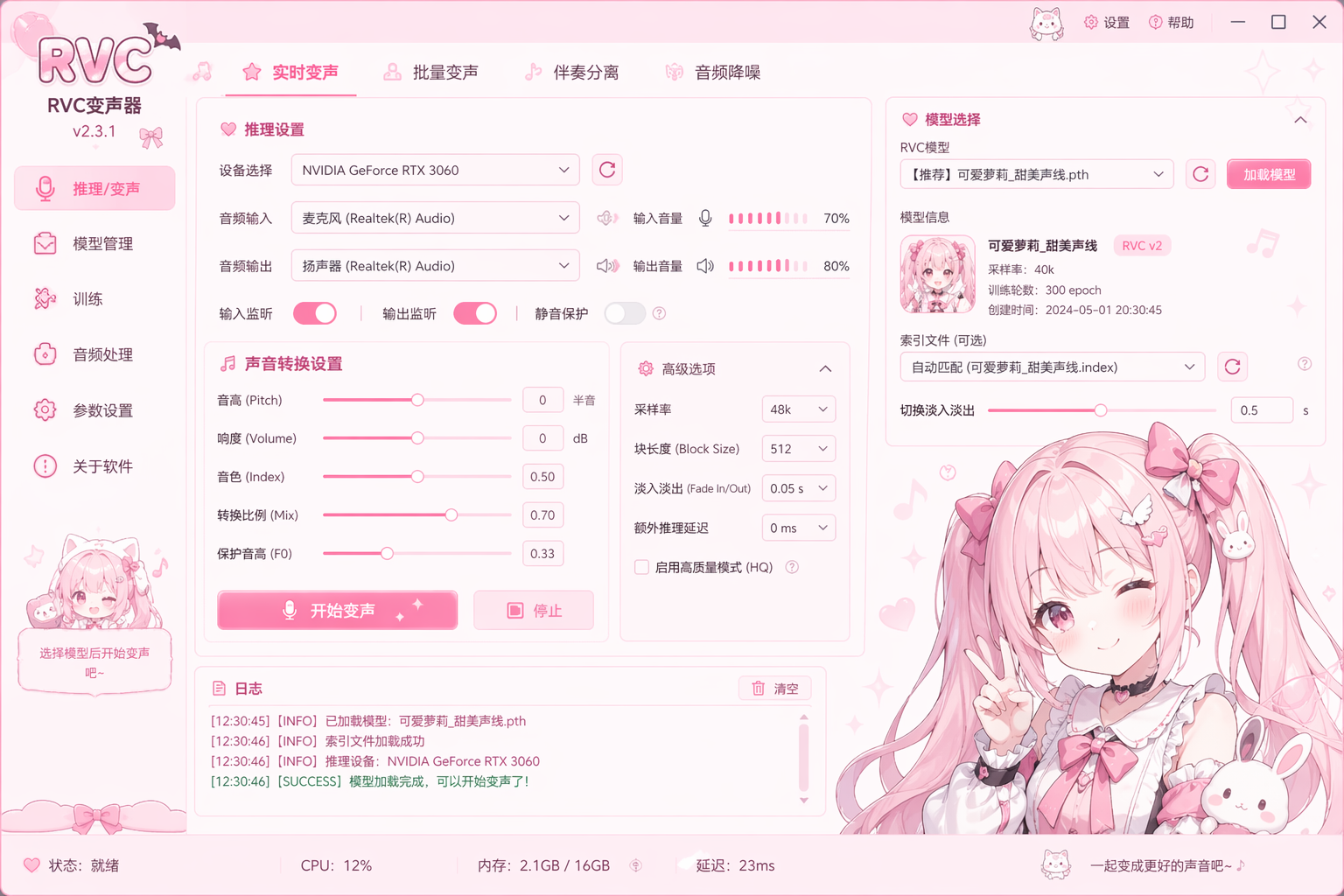
支持在语音通话、游戏直播中实时变换声音,延迟低于50ms,几乎无感知。
采用先进的深度学习模型,推理速度优化,平均延迟仅30-80ms。
基于MIT协议开源,代码完全免费可见,支持自部署和二次开发。
兼容RVC、So-VITS等多种变声模型,海量音色任你选择,一键切换。
点击上方下载按钮,获取Windows或Mac版本安装包
解压后双击运行,无需复杂配置,开箱即用
导入喜欢的变声模型,开始你的变声之旅
解决RVC变声后他人听不见的问题,手把手教你配置VB-Audio虚拟声卡实现全局变声,解决音频路由闭环问题。
Apple Silicon芯片(M1/M2/M3)RVC变声器优化指南,通过Homebrew配置CoreML环境、优化内存分配及索引检索策略,解决Mac平台卡顿与报错问题。
RVC变声器缓存膨胀解决方案,通过迁移模型文件、清理临时缓存、调整索引检索频率,释放70%以上磁盘空间,降低40%显存占用。
RVC 全称 Retrieval-based Voice Conversion(基于检索的语音转换),是当下主流的开源 AI 智能变声模型。它依托 VITS 深度学习架构,区别于传统硬件、软件调音变声,凭借检索匹配技术实现高仿真人声转换,也是目前直播、游戏、音频创作最常用的变声工具。
从技术原理来看,RVC 核心分为四步运作。首先通过 HuBERT 预训练模型提取人声内容特征,剥离说话人的原生音色、声纹,只保留语义、语速、语调、情绪和咬字节奏;其次启动特征检索机制,从提前训练好的音色模型库中,精准匹配与当前语音节奏最契合的目标音色向量;再将纯净内容特征与检索到的音色特征融合替换,杜绝原声泄露;最后经由 VITS 声码器重构音频,生成自然流畅的全新人声。它最大优势是低资源训练,仅需 5–10 分钟纯净人声,普通电脑就能训练专属音色,且保留呼吸感、语气细节,无机械失真。
RVC 与传统变声器有着本质区别。传统变声器仅靠简单的音调升降、滤波降噪、频率均衡做物理波形修改,没有 AI 学习能力,只有固定的萝莉、大叔、男女声预设,音色僵硬、电子音浓重,唱歌极易跑调,无法还原真人语气。而 RVC 是 AI 深度学习建模,能高度复刻真人声线细节,支持自定义训练任意音色,实时变声延迟极低,唱歌、说话都自然真实,还能修复音准,这是传统变声器无法做到的。
游戏开黑是最常用场景,低延迟实时变声,可切换动漫、网红音色,隐藏原声,兼顾娱乐和隐私;直播与虚拟主播领域,主播可打造专属人设声线,虚拟人搭配定制 RVC 音色,互动整活效果拉满;音频创作上,可实现 AI 翻唱、跨歌手音色转换,制作歌曲二创;短视频、影视配音中,能一键替换解说、角色声线,节省配音成本;同时也适用于线上社交,通过变声隐藏真实声线,保护个人隐私。